Evaluation Framework
Best AI Agents for Google Ads: How to Evaluate the Shortlist

Compare categories first. Google product assistance, AI agents, PPC platforms, scripts, and generic chat tools do not solve the same job.
Evaluate the best AI agents for Google Ads by what they finish after the recommendation: account review, reporting, approvals, and account changes.
Key takeaway
The best Google Ads AI agent is the one that finishes the weekly account job after the recommendation, not the one that produces the longest suggestion list. If the team still rebuilds the report, rewrites the rationale, and chases approval by hand, the tool did not really save time.
Parallel AI is the AI agent platform for Google Ads work. Agencies and in-house teams hand off research, reporting, and optimization on connected accounts, and every account change the agent drafts waits for a person to approve it. Most tools in this category stop at recommendations. Parallel finishes the work in docs, spreadsheets, and reports a client or a lead can act on.
Start the shortlist by separating categories. Smart Bidding, AI Max, Recommendations, Performance Max, and manager accounts work inside Google Ads. AI agents, optimization platforms, scripts, and general AI tools handle different parts of the review, reporting, and approval work around the account.
Parallel should be judged on that finish line. It works from the connected Google Ads account, turns the review into docs, sheets, and reports someone can act on, and keeps drafted account changes waiting for human approval.
This guide ranks decision criteria, not affiliate relationships. Every recommendation should be testable during a short account-review pilot.
- Score options on account context, recommendation usefulness, reporting quality, approval controls, and cost-to-value fit.
- Require visible methodology for ranked claims; do not trust lists that skip criteria and weights.
- Shortlist ties are broken with a controlled Google Ads pilot, not static feature comparisons.
- A strong fit combines commercial judgment, human review, and reporting teams can share rather than only surfacing automation ideas.
Monday starts with a familiar paid-search problem. The account manager has already spotted rising CPA in one Search campaign, the analyst has a half-finished search terms export, and the client summary still needs a clean explanation before any bid, budget, or negative keyword change moves forward.
DEFINITION
Best Google Ads AI agent
The best option is the one that helps a team move from account evidence to a reviewed next step with the least rework. It is not the option with the longest feature list or the fastest first answer.
shortlist definition
That scene is where most evaluations go wrong. The demo answer sounds sharp, but the real job begins after the answer: check the search terms report, pull Change history, rewrite the rationale for the weekly check-in, decide whether the recommendation belongs in the account now, and keep the approval step visible. If the tool drops the team at that boundary, it did not finish the work.
So It defines best in operational terms. Best means the weekly account review gets shorter, the prioritization gets clearer, the reporting gets easier to share, and higher-impact changes stay under control. The tool should remove time from the messy middle between finding the issue and approving the next step.
Google video·Accelerate with Google
enhance Performance Max campaigns with audience signals
This Google tutorial is a stronger shortlist and buyer-guide reference than a general announcements clip because it focuses on one specific optimization workflow professionals already use.
Source reference·Optmyzr
PPC operations and Google Ads review fit
Editorial graphic contrasting broad PPC operations software with a Google Ads-first account review and reporting process.
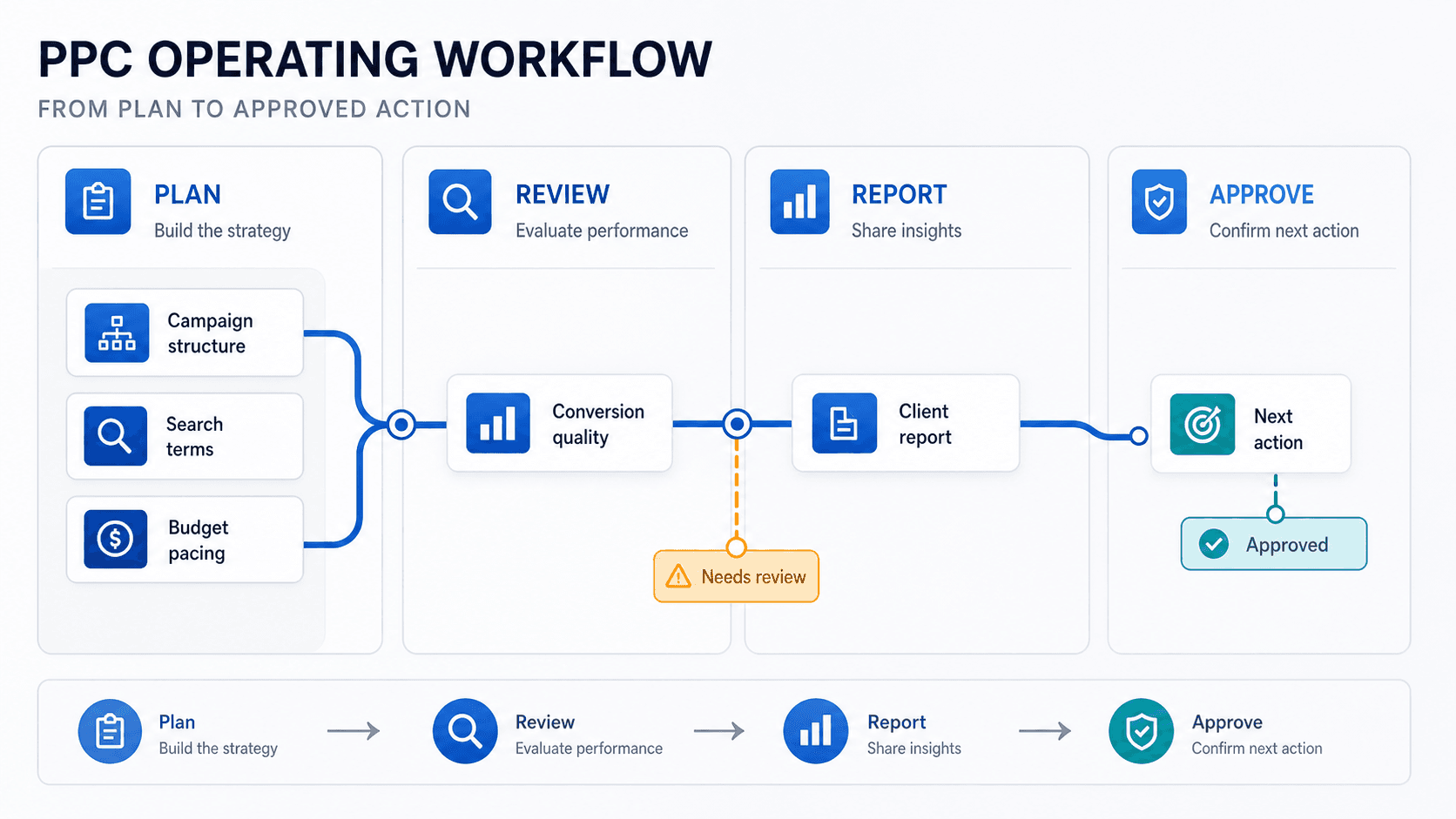
Best is the tool that keeps the job moving after the first recommendation.
Once best is defined that way, the criteria change. A shortlist should not reward clever prompting in isolation. It should reward the systems that can carry account context, prioritization, reporting, and review farther than a chat transcript.
That is why the criteria below lean on account context, execution quality, governance, reporting readiness, and cost-to-value fit. Those are the places where a real PPC team loses the week, not the places where a vendor demo usually spends its time.
| Criterion | Why it matters |
|---|---|
| Account context depth | Generic AI output is easy to generate. connected-account analysis is what prevents wasted cycles. |
| Workflow execution quality | The best tools reduce the number of handoffs between diagnosis, planning, and output. |
| Governance and review | High-impact Google Ads changes need controls, not just speed. |
| Collaboration and reporting readiness | Account-review docs, sheets, and client or exec summaries matter in real weekly workflows. |
| Cost-to-value fit | Price only matters after you model the recovered labor and rework reduction. |
The right criteria score the work after the first answer, not the answer alone.
Weighting matters because every team says all criteria are important until it has to choose. The honest model puts more weight on the moments that regularly delay the weekly review: weak account context, vague prioritization, cleanup on the report, and uncertainty around approval.
For most paid-search teams, recommendation usefulness and connected-account analysis deserve the most weight because they decide whether the review starts with a real point of view or a pile of plausible ideas. Throughput, reporting, and governance come next because they determine whether that point of view survives contact with the rest of the team.
| Criterion | Weight | What good looks like | Disqualifier risk |
|---|---|---|---|
| connected-account analysis quality | 22 | The system reads real account context, recent change history, and business constraints well enough to produce a trustworthy first pass. | Output sounds plausible but stays generic once the workflow gets specific. |
| Recommendation usefulness | 20 | Actions are ranked, rationale-backed, and usable by another teammate with minimal translation. | The system produces ideas, not a usable decision sequence. |
| Workflow throughput | 15 | The weekly cycle becomes faster without turning reports and summaries into a cleanup exercise. | Time saved in chat is lost again in docs, sheets, or review cleanup. |
| Governance and control | 15 | Approval ownership, auditability, and reviewer confidence remain visible on higher-risk actions. | The team cannot explain who owns the recommendation once it leaves the tool. |
Weights are useful only when they reflect the review that actually happens each week.
Before any brand comparison starts, sort the category correctly. Google-native AI, AI agents, optimization platforms, scripts, and general AI tools are not five versions of the same product. They answer different questions in the account.
That category split saves time because it stops the shortlist from asking one system to do another system's job. Google Ads native AI is strong when the team wants in-product tuning. Platforms and scripts are strong when the logic is stable and the team accepts upkeep. AI agents matter most when the missing piece is connected-account diagnosis, prioritization, reporting, and review.
AI agent platforms
Best for teams that need connected-account analysis plus docs, sheets, and shareable account-review summaries.
Google's native Search AI stack
Best for in-product Search work built around broad match, Smart Bidding, responsive search ads, and AI Max for Search campaigns where relevant.
Automation platforms and scripts
Best for deterministic execution when the logic is stable and the maintenance burden is acceptable.
General-purpose AI tools
Best for lightweight drafting, but usually weaker on live account context and approval-heavy workflows.
A clean shortlist starts by admitting that not every tool is trying to finish the same job.
With the categories in place, the shortlist becomes clearer. A serious evaluation set should include the Google-native path, the AI-agent path, the platform path, and the script baseline, because that is how a real buyer sees the decision in practice.
The point is not to pretend there is one timeless winner. The point is to run a fair trial against the same recurring account job and see which option produces the strongest combination of account understanding, reporting quality, and review confidence for the team that will actually use it.
| Option | Category | Best fit | Main tradeoff |
|---|---|---|---|
| Google's native Search AI stack | Native Search AI | Teams centered on in-product Search tuning and campaign execution | Does not replace external workflow packaging or multi-account operations |
| Parallel AI | AI agent platform | Teams needing analysis plus reporting workflows | Requires standardization to get the most value |
| Optmyzr / Adalysis class tools | Optimization platform | Teams focused on managed automation depth | Can still need separate workflow packaging |
| Google Ads Editor + scripts | Script baseline | Technical teams with strong maintenance discipline | High upkeep and less AI-led prioritization |
A shortlist is useful only if each option has a fair chance to finish the same recurring job.
Scores are helpful only after the obvious no-fit cases are gone. In paid media work, disqualifiers usually appear early: weak account context, poor auditability, vague reporting, or no clear explanation of how reviewed changes stay under control.
This is the mistake behind many best-tool pages. They assume every candidate deserves to be ranked even when one category cannot realistically support the team's weekly review. A script baseline may be excellent for stable maintenance work and still be a poor fit for diagnosis-heavy reporting work. A general AI tool may draft quickly and still fail once the account gets specific.
So disqualify first, score second. If the system cannot show how the recommendation was built, cannot package the result into something the next person can use, or cannot explain where review happens before higher-impact changes, it should leave the shortlist before the weighting model begins.
Keep on shortlist
- It can explain how recommendations are reviewed before higher-impact changes.
- It can produce account-review output with minimal rewrite on a recurring weekly job.
- Its account context holds up once the review gets specific.
Drop before scoring
- The output still reads like generic advice after you open the actual account.
- The team cannot tell who owns the recommendation once it leaves the tool.
- The weekly summary still has to be rebuilt by hand.
Disqualifiers save more time than a neat scorecard ever will.
The next guardrail is freshness. Google-native AI changes quickly, platform vendors revise positioning, and trial language drifts. A shortlist without a dated source review is not disciplined buying guidance. It is stale copy that happens to rank.
That does not mean every paragraph needs a footnote. It means the ranking needs visible source discipline: when the sources were reviewed, what workflow was used in the trial, and where each option is not a fit. Without that, the page cannot tell the difference between current product truth and leftovers from an older market.
| Source item | Why it matters |
|---|---|
| Time-stamped source review | Prevents the ranking from freezing old product language or stale feature availability into a permanent claim. |
| Reviewer notes from one recurring workflow | Shows how the candidate performs on real work instead of demo-friendly edge cases. |
| One explicit not-fit note per option | Makes the ranking useful to a practitioner who needs to rule tools out, not just gather options. |
Freshness is part of the evaluation method, not a cleanup step after publication.
A shortlist becomes real when the team commits to one recurring account job and runs every candidate against it. The job should already matter enough to measure clearly: weekly account health, a budget pacing review, a search terms cleanup, or a client summary that regularly eats time.
That trial design matters because it keeps the comparison honest. Every option sees the same account complexity, the same reporting need, and the same approval standard. The tie-break is not who sounds smarter in chat. The tie-break is who helps the team finish the job with less rework.
01
Week 1: baseline one recurring workflow
Measure diagnosis time, planning time, summary rework, and approval friction on a live weekly cycle.
02
Weeks 2-3: run the shortlist against the same job
Use the scorecard on identical workflow prompts and the same account complexity level.
03
Week 4: choose by workflow lift
Select the option that improves quality and throughput without weakening governance.
One recurring job tells the truth faster than ten disconnected demos.
The trial itself should stay close to the messy middle the team is trying to improve. It is not enough to ask whether a candidate finds the issue. The team has to ask whether the result survives the summary, the report, and the approval conversation that follow.
That is why the best tests measure more than time to first answer. They measure whether another teammate can pick up the output, whether the rationale still holds after account review, and whether the proposed change is easy to approve, reject, or revise.
| Trial check | What to watch |
|---|---|
| Run the same weekly diagnosis | Use the same account-health, pacing, or search terms job across every shortlisted option. |
| Score recommendation quality | Check ranking, rationale, and whether the next person agrees on what matters first. |
| Measure report rework | Track cleanup time on client summaries, exec updates, and reporting tables. |
| Check review clarity | Log whether governance and review controls are explicit enough for paid-media production use. |
The trial should test whether the recommendation survives contact with the rest of the week.
When the trial ends, the team should have more than a winner. It should have a reusable record of what was tested, what failed early, what stayed credible, and why the final recommendation made sense for this account shape and team shape.
That record is what lets finance, leadership, or the next account lead revisit the decision without repeating the whole evaluation from scratch. It also keeps the page honest when a vendor changes product scope later, because the team can rerun the same job and compare the new result against the old reasoning.
| Part of the review | Why it matters |
|---|---|
| Tested workflow definition | Define the exact recurring job, account scope, and expected report or summary before any option is scored. |
| Reviewer notes and disqualifiers | Capture why a recommendation was accepted or rejected, and log the workflow gaps that remove an option from the shortlist. |
| Time-stamped sources | Keep pricing, feature, and Google-native references dated so the shortlist remains defensible when the market shifts. |
| Final recommendation summary | Summarize the winner, runner-up, and not-fit cases in the same review so the buying decision is reusable across the team. |
If the evaluation cannot be reused, it was not careful enough the first time.
This is where most best-tool content loses the plot. A leaderboard sounds permanent, but paid-search tooling is not permanent. A decision summary is more durable because it records the account job, the review standard, the disqualifiers, and the reasons the winner stayed ahead on that date.
That format also respects how teams actually buy software. They do not need a timeless winner. They need a clear answer they can defend inside the business this quarter, with enough detail to revisit it when Google changes the platform or a vendor changes product scope.
So write the ranking the same way you would write a serious internal recommendation. State what was tested, what failed, what stayed credible, and what the winning option improved in the weekly review. That turns a best-tool page into buying guidance instead of marketing theater.
A decision summary can be updated honestly; a leaderboard usually cannot.
The fastest way to judge another ranking is to look for the missing work. If the page skips methodology, ignores category boundaries, hides its source dates, or refuses to say where a tool is a poor fit, it is probably ranking brand familiarity instead of product truth.
| Red flag | What it usually means |
|---|---|
| No methodology section | The ranked claims were never tied to a visible process. |
| No category split | Native platform AI, automation software, and AI agents are being collapsed into one false comparison. |
| No trial record | The page is relying on marketing copy instead of real account-review testing. |
| No not-fit cases | The page is trying to collect every buyer instead of guiding the right one. |
A ranking that hides its missing work is usually not worth trusting.
The last adjustment is team shape. Agencies, in-house teams, and solo specialists carry different approval paths, different reporting pressure, and different tolerance for setup or upkeep. That changes what the shortlist should reward, even when the account problem looks similar on the surface.
Agencies tend to care most about multi-account throughput, client-summary quality, and a review path that survives handoff across account managers and analysts. In-house teams often care more about decision quality, internal approval fit, and whether the recommendation can travel cleanly into finance or leadership conversations. Solo specialists care most about whether the tool actually removes repeated weekly work instead of adding setup drag.
| Team type | What should carry the most weight |
|---|---|
| Agencies | Multi-account throughput, collaboration model, client-ready output quality, and governance on high-impact changes. |
| In-house growth teams | Decision quality, recurring workflow speed, and approval controls that fit an internal review chain. |
| Solo specialists | Cost-to-value fit, account-context quality, and whether the tool reduces repeated weekly work without setup drag. |
On Monday morning, pick one recurring review, pull Search terms, Change history, Recommendations, and last week's summary, then see which option finishes the job with the least rework.
Use the current Google videos, Help pages, public announcements, and product visuals below to confirm availability, setup details, and reporting limits.
Source reference·Opteo
Recommendations and reporting fit
Editorial graphic contrasting recommendation-led account management with deeper Google Ads review and reporting work.
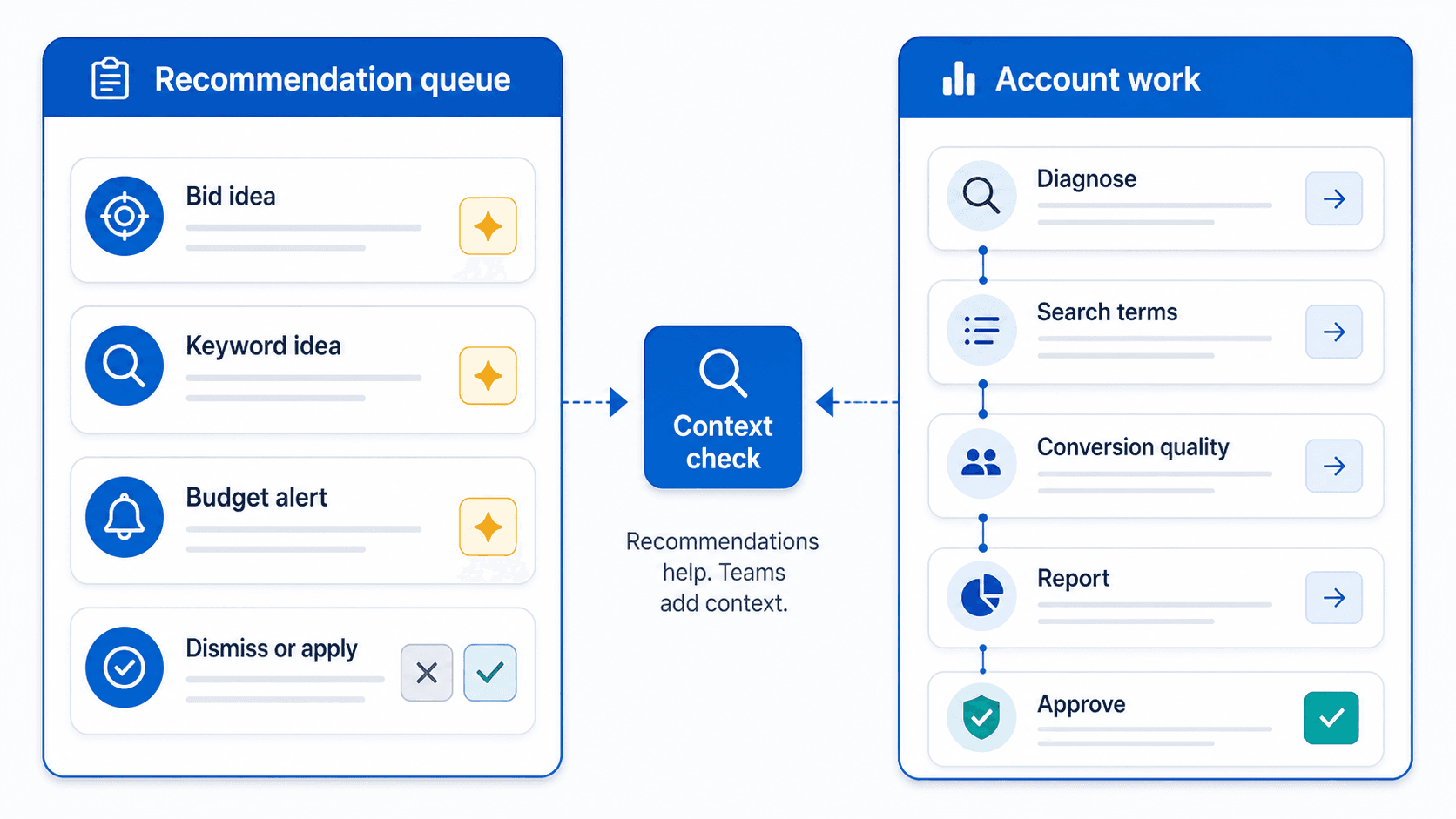
Google documentation·Google Ads Help
Google's guide to AI Mode and AI Max ads
Use Google's official overview of broad match, Smart Bidding, and responsive search ads as the baseline for any native Search AI claim in these guides.
Open official guideGoogle documentation
Google's current documentation for AI Mode and AI Max built on broad match, Smart Bidding, and responsive search ads.
Official Smart Bidding reference for Google's automated bid optimization systems.
Official overview of AI Max for Search campaigns, including matching, creative, reporting, and controls.
Official reference for Google Ads Recommendations and how they use account history, campaign settings, and trends.
Official Performance Max reference for campaign scope, inventory, goals, asset groups, and optimization context.
Official manager-account reference for agencies and teams managing multiple Google Ads accounts from one place.
Official reference for using the search terms report to review which searches triggered ads and identify keyword or negative keyword updates.
Official reporting reference for Report editor, predefined reports, saved reports, and manager-account reporting.
Official ad-eligibility guidance for AI Overviews and AI Mode placements in Google Search.
Additional documentation
Practical review of which Google Ads AI features are safe starting points and which ones still require tighter human oversight.
Useful current framing for what Google is shipping natively in Ads and Analytics and where those agentic features sit relative to external workflow tools.
Recent independent analysis of AI Max tradeoffs, useful for framing where broader reach can create efficiency risk.
Workflow-oriented comparison of native Google Ads editing and rule tooling versus a team-scale automation layer.
- Blog homeBrowse every published Google Ads guide from one editorial index.
- Google Ads AI agent: complete guideThe pillar guide covers the category definition, the adoption model, and where the agent fits real Google Ads work.
- ResourcesMove between the definition page, pricing, product walkthrough, and trust pages.
- About Parallel AISee the company mission, editorial standards, and operating principles behind the product.
- SecurityReview the public data-handling, account-connectivity, and approval-control framing used throughout the published guides.
- Google Ads AI Agent Pricing: Seats, Account Limits, and Total CostFor testing pricing against account load, team shape, day-to-day fit, and the manual hours still left after rollout.
- Google Ads Copilot Alternatives: Native AI, PPC Platforms, Scripts, and AgentsFor buyers searching copilot alternatives who need the right category before comparing brands.